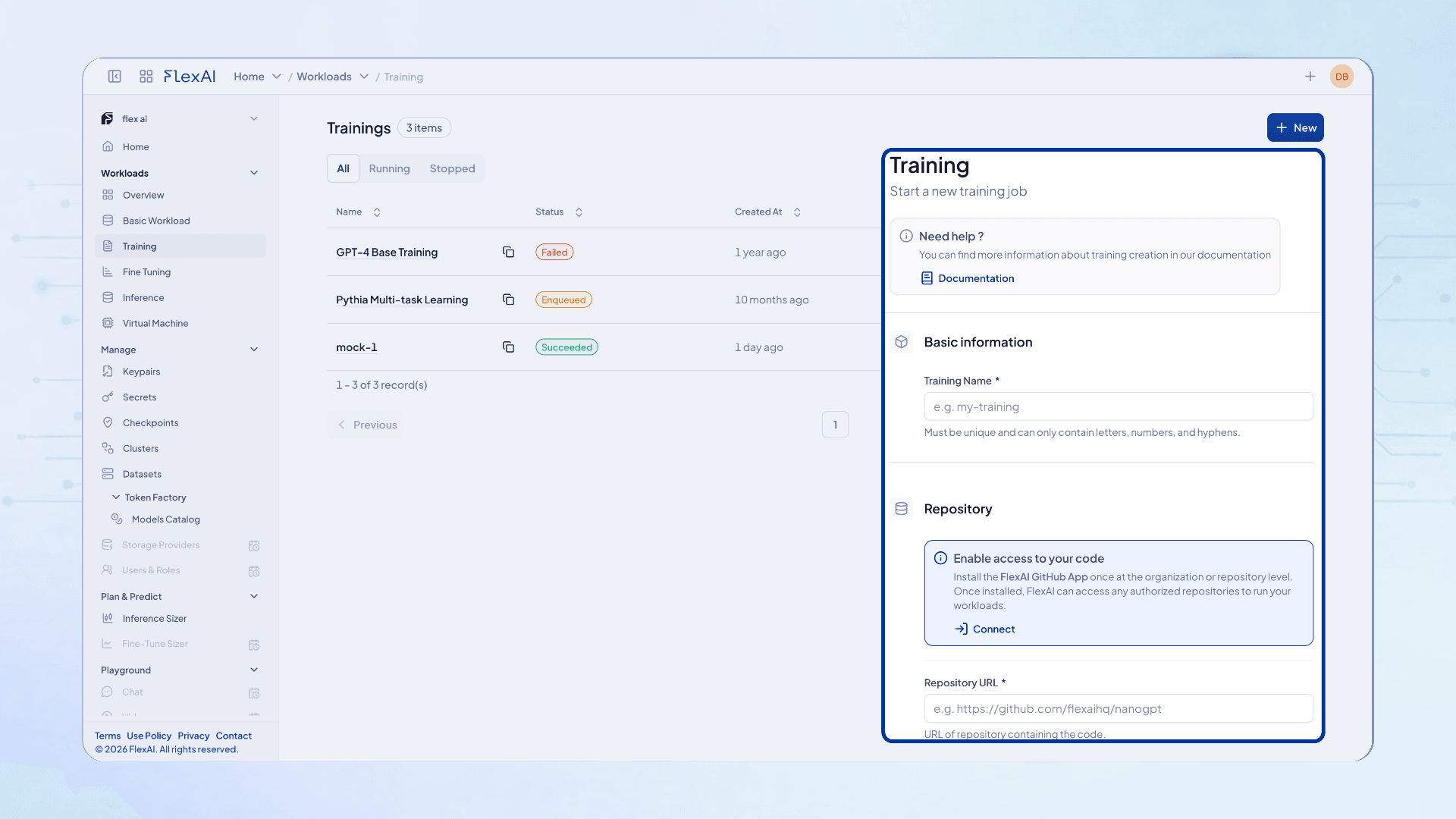
Intent-driven training,end to end
Bring your datasets and code; FlexAI handles orchestration, checkpoints, and workload placement so your team stays in motion.
Train and post-train the models that power your agents, then deploy winners back into Token Factory, dedicated endpoints, or Agent SDK workflows.
Two phases. One rhythm
Large Scale Support
- 1 to 1000s of GPUs
- Multi-node distributed
- Multi-region compute
Performance & Resilience
- Parallelized execution
- Auto checkpointing
- Managed data pipelines
Built-in Observability
- TensorBoard · Visualize metrics and graphs
- Weights & Biases · Track experiments at scale
- Grafana · Infrastructure monitoring
A calm interface for serious work
A simple control point for end users and admins, with governance and visibility when you need it.
Teams keep velocity
A few words from builders using FlexAI for training and deploying models.
"Compared to other platforms I have used, FlexAI provides a more cost effective and hassle free experience for training and deploying my models.
LegML
"FlexAI enabled us to prove the value of our model in record time and make it to Y Combinator.
Dollyglot.com
"The ability to manage compute resources across multiple cloud providers through a unified interface is a game changer.
Pixelcut
Sizing a training run? Use the GPU savings calculator to compare H100/H200 costs against hyperscalers, or work out when serverless stops paying off. Need dedicated capacity for the largest jobs? See dedicated endpoints.
- 1Pick a blueprint for your model family and stage
- 2Set constraints: budget, speed, region, reliability
- 3Launch. Observe. Promote the winner
Frequently Asked Questions
More managed AI services: inference, fine-tuning, and the platform overview.