LegML + FlexAI: Ready for French Business Law
Everyone assumes "bigger model = better results." LegML set out to prove otherwise.
LegML fine-tuned a 32B-parameter legal LLM that outperformed a frontier model on their domain benchmarks while cutting both training and serving costs. With FlexAI as the AI infrastructure management platform, they trained reliably at scale, deployed efficiently, and demonstrated that smaller, specialized, and sovereign can beat larger, generic, and outsourced.
The mission: accuracy, sovereignty, and economics
LegML's goal was simple: deliver higher accuracy for legal tasks with a model that could run inside a company's own infrastructure where no data leaves the platform, no black-box APIs, and no lock-in. They combined supervised fine-tuning on legal workflows (drafting, compliance, Q&A) with Group-Relative Policy Optimization (GRPO) to raise reasoning quality, citation accuracy, and legal consistency.
The constraint: do it on a predictable budget and timeline.
What was in the way
Before FlexAI, LegML hit the same walls most teams trying to fine-tune a model face:
- Inconsistent capacity and hard limits on a popular European neo-cloud (strict quotas; studio capped at ≤20B models).
- High cost and lower performance relative to FlexAI's H100/H200 clusters when they tested elsewhere.
- Ops overhead everywhere: manual cluster setup, checkpoint management, and ad-hoc monitoring elongated each run.
The net effect: unreliable schedules, unpredictable spend, and engineering time spent on infrastructure instead of model quality.
What changed with FlexAI
FlexAI removed the challenges faced by LegML, so they could focus on the model:
FlexAI pins the full stack per workload (CUDA/ROCm, cuDNN, NCCL, drivers, container image, Python deps) and versions it as an immutable spec. Artifacts (datasets, checkpoints, logs) are tracked in a versioned object store with lineage.
Jobs use DDP/FSDP/ZeRO with mixed precision (bf16/fp8 where supported). Checkpointing is sharded and incremental; resume is idempotent after spot preemption or node drain.
Schedulers match the job profile to the right accelerator class and memory tier. Train/fine-tune on premium NVIDIA clusters; serve on cost-efficient accelerators with graph/runtime optimizations and quantization, without changing application code.
The results
LegML's Hugo outperformed Mistral's flagship model across every benchmark, delivering +10% higher factual precision, with 50% fewer parameters and 75% lower compute cost.
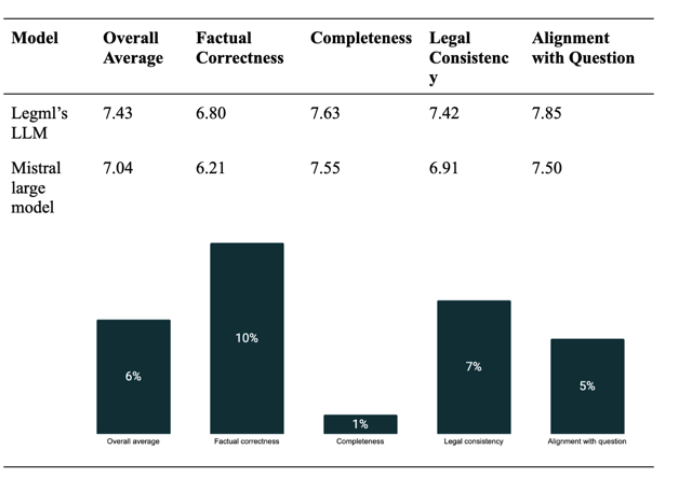
Two independent legal experts reviewed outputs and concluded Hugo produced more accurate and complete answers for legal reasoning tasks.
LegML describes the result as "peace of mind": every workload completed successfully and cost-effectively, so the team could iterate on data and training signals instead of babysitting clusters.
Why this matters
Keep models and data where they must live (on-prem, private cloud, or sovereign cloud) without sacrificing iteration speed.
Domain-specific training plus the right workload platform beats brute-force scale, especially where precision and auditability matter.
Use premium silicon where it pays off (training), then serve on lower-cost accelerators without refactoring. The economics compound.
A reproducible blueprint for vertical LLMs
LegML and FlexAI are turning this into a repeatable blueprint: full-parameter fine-tuning on curated sector corpora, with continuous learning pipelines and hybrid human + LLM evaluation.
The approach is already moving from law into finance, insurance, and public administration: domains where precision, governance, and sovereignty are non-negotiable.
Build your own domain-specific LLM
If you're exploring a domain-specific LLM, and want accuracy, control, and predictable economics, let's talk.
Get in touch