The results
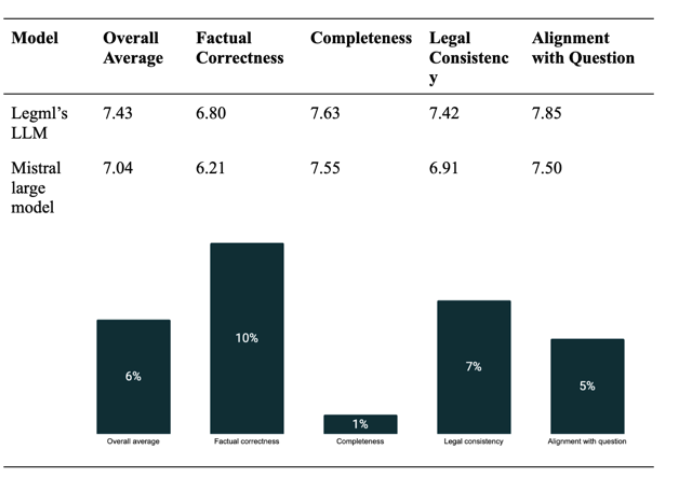
Legml’s Hugo outperformed Mistral’s flagship model across every benchmark, delivering +10% higher factual precision, with 50% fewer parameters and 75% lower compute cost.
Accuracy
LegML’s 32B model (“Hugo”) outperformed a leading frontier model on LegML’s benchmark suite, including +10% higher factual precision, with 50% fewer parameters.
Training cost & speed
14 days on FlexAI-provisioned distributed H100 (via partner capacity) for approximately €22,500 total.
Serving economics
Hugo runs efficiently on a single H200 GPU at $3.15/hour, about $9,072 for six months of continuous operation.
Alternative baseline
A comparable 70B model would require 2× B200 at $6.25/hour, roughly $36,000 over the same period.
Payback: ~5.3 months
In plain terms, Hugo delivers higher accuracy with ~4× lower operating cost than the larger alternative.
Two independent legal experts reviewed outputs and concluded Hugo produced more accurate and complete answers for legal reasoning tasks.
LegML describes the result as “peace of mind”: every workload completed successfully and cost-effectively, so the team could iterate on data and training signals instead of babysitting clusters.
Why this matters
- Sovereign by design: Keep models and data where they must live—on-prem, private cloud, or sovereign cloud—without sacrificing iteration speed.
- Smaller can be smarter: Domain-specific training plus the right workload platform beats brute-force scale, especially where precision and auditability matter.
- Runway, not waste: Use premium silicon where it pays off (training), then serve on lower-cost accelerators without refactoring. The economics compound.
A reproducible blueprint for vertical LLMs
LegML and FlexAI are turning this into a repeatable blueprint: full-parameter fine-tuning on curated sector corpora, with continuous learning pipelines and hybrid human + LLM evaluation.
The approach is already moving from law into finance, insurance, and public administration—domains where precision, governance, and sovereignty are non-negotiable.
FlexAI remains the foundation: a single platform that handles orchestration, scaling, and monitoring so teams can spend their time on data, training signals, and product.
%201.png)