White-label the AI Factory
Turn hardware infrastructure into a production-ready AI platform in weeks
Launch GPUaaS and managed AI services on a unified enterprise-grade platform across cloud and on-prem.
Looking to provide compute or models instead? See Partnerships.
Results
Customers and Outcomes
Enterprises
Deploy secure, governed private & hybrid AI Clouds on any hardware
System Integrators
Create & deliver repeatable White-labeled AI infrastructure platforms
75%
Faster Time-to-Launch
Hardware to GPUaaS and AI services in weeks, not quarters
40%
Higher Utilization
Tiering and burst tiers reduce stranded capacity
2×
Revenue Streams
Higher margin managed AI services supplement GPUaaS revenue
For Your Customers
AI platform services for end-users
A portfolio of revenue-generating AI services your customers can consume immediately.
Dedicated Inference with Autoscaling
Token-based Serverless Inference
Offline Batch Inference
Managed Checkpoints & Post-training
Jupyter NB, Grafana & TensorBoard
Metering, Billing Hooks & SKU Mapping
GPUaaS: VMs & Bare Metal
Fractional & Time-sliced GPUs
GPU & Network Isolation, VPC
Agents & Pulumi IaC
Portal, Identity & Multi-tenancy
Governance & Compliance
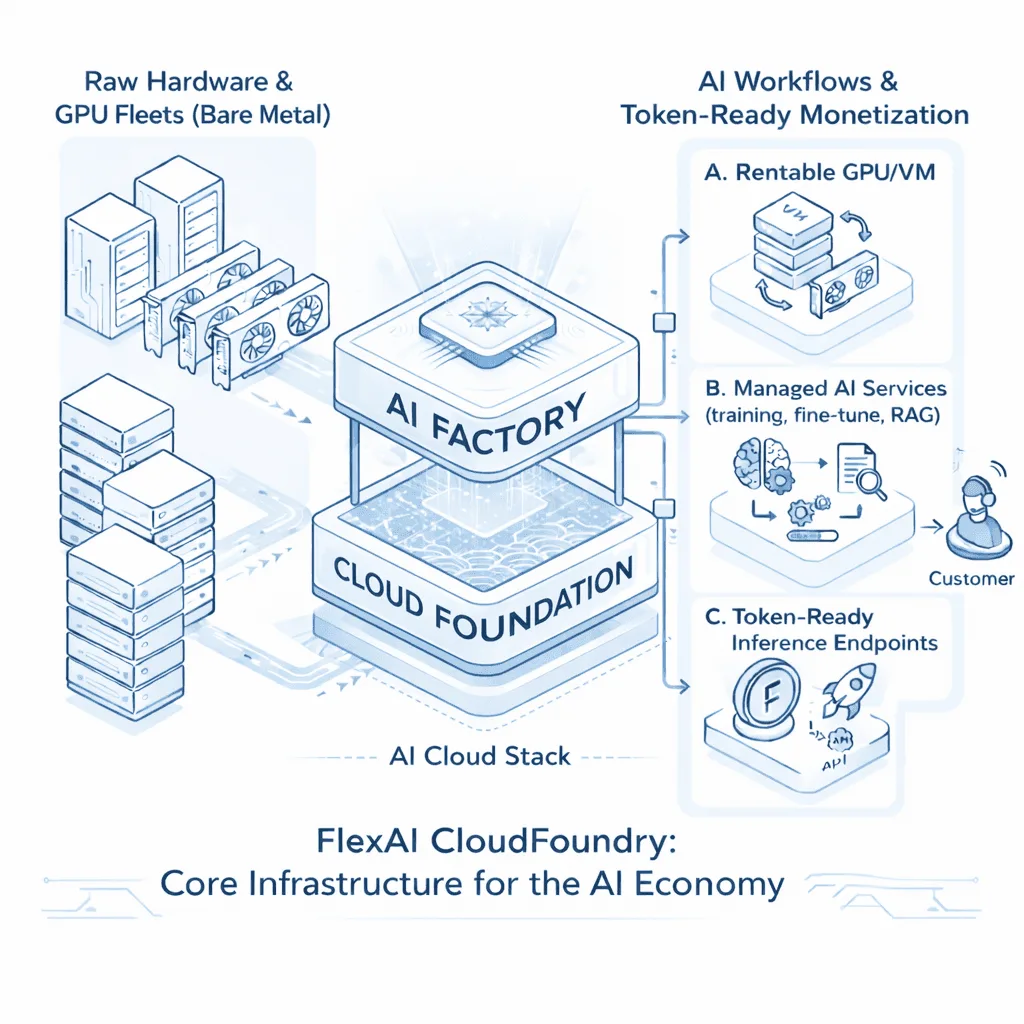
Platform
The FlexAI AI Factory platform
Two tightly integrated layers that transform bare metal into a complete, revenue-generating AI cloud platform.
AI Services Layer
- Managed AI services (inference, fine-tuning, training, RAG)
- Token & usage-based monetization
- Blueprint-based templates
- Governance, Reliability & Observability
- HPC workloads via SLURM on Kubernetes
Cloud Foundation
- Intent-driven control plane for automated infrastructure management
- GPUaaS and VM infrastructure provisioning
- Mixed GPU fleets (NVIDIA, AMD, etc.) with unified scheduling
- Unified cloud pool with burst-to-cloud for on-demand capacity
- S3-compatible object storage or local storage options
Enterprise-ready
SOC2 Type II certified & GDPR compliant
Why AI Factory
Why the FlexAI AI Factory
An intuitive, vendor-agnostic platform with scalable infrastructure, built to get you to production fast.
Intuitive Platform
- 1-click Platform: Unified access with role-specific logins via Natural language, Web-UI, CLI, API, Python SDK
- Deployment Blueprints: Prebuilt application templates for faster production
Infrastructure Freedom
- Unified Pooling: Combine resources into a single, manageable collection
- No Vendor Lock-in: Run mixed GPU fleets (NVIDIA, AMD, etc.) & focus on $/GPU/Hour
- Reusable Packages: Reproduce multi-tenant deployments with IaC automation & free up DevOps
Scalable Implementation
- Networking: InfiniBand or RoCE-v2 Ethernet scale-out networking and NVLink for high throughput scale-up
- Storage: S3-compatible object storage with optional local storage for immediate access
- Cloud: Multi-region pools, burst to cloud for extra on-demand capacity
Launch your AI cloud
Transform your infrastructure into a dynamic, revenue-generating AI cloud platform.
Schedule a consultation